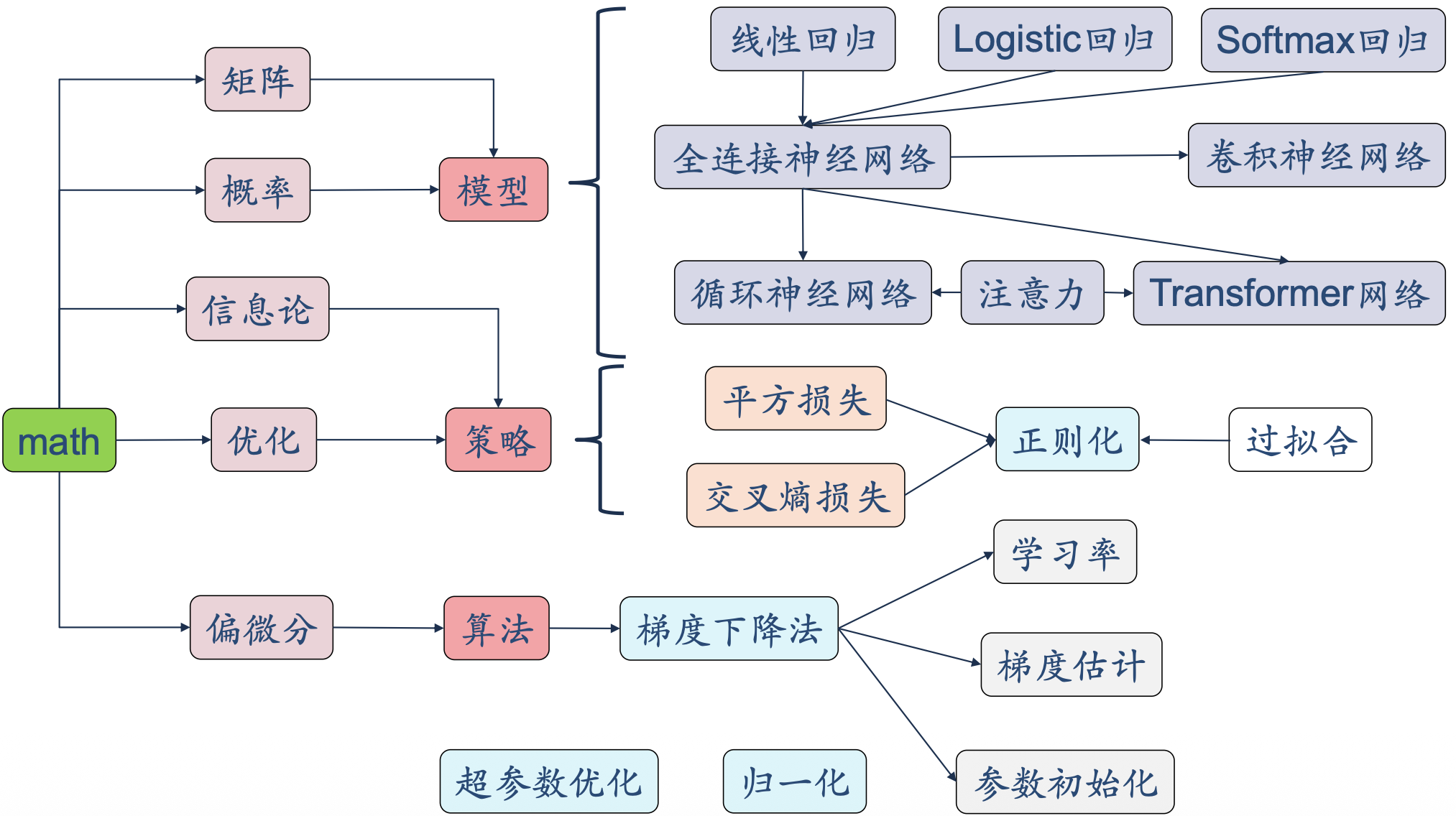
注意力机制与 Transformer
注意力机制
鸡尾酒会效应
当一个人在吵闹的鸡尾酒会上和朋友聊天时,尽管周围噪音干扰很多,他还是可以听到朋友的谈话内容,而忽略其他人的声音。
同时,如果未注意到的背景声中有重要的词(比如他的名字),他会马上注意到。
如何实现
- 自下而上 — 汇聚(pooling)
- 自上而下 — 会聚(focus)
人工神经网络中的注意力机制
注意力模型
软性注意力机制(soft attention mechanism)
按照概率混合所有词
- 计算注意力分布
:
其中
- 根据
来计算输入信息的加权平均:
注意力打分函数
| 模型 | 打分函数 |
|---|---|
| 加性模型 | |
| 点积模型 | |
| 缩放点积模型 | |
| 双线性模型 |
注意力机制的变体
- 硬性注意力(hard attention)
- 键值对注意力(key-value pair attention)
- 用
表示 个输入信息
- 用
- 多头注意力(multi-head attention)
- 用多个查询
并行输出多组信息
- 用多个查询
- 结构化注意力(structural attention)
- 层次化注意力
- 指针网络(pointer network)
- 我们可以只利用注意力机制中的第一步,将注意力分布作为一个软性的指针(pointer)来指出相关信息的位置。
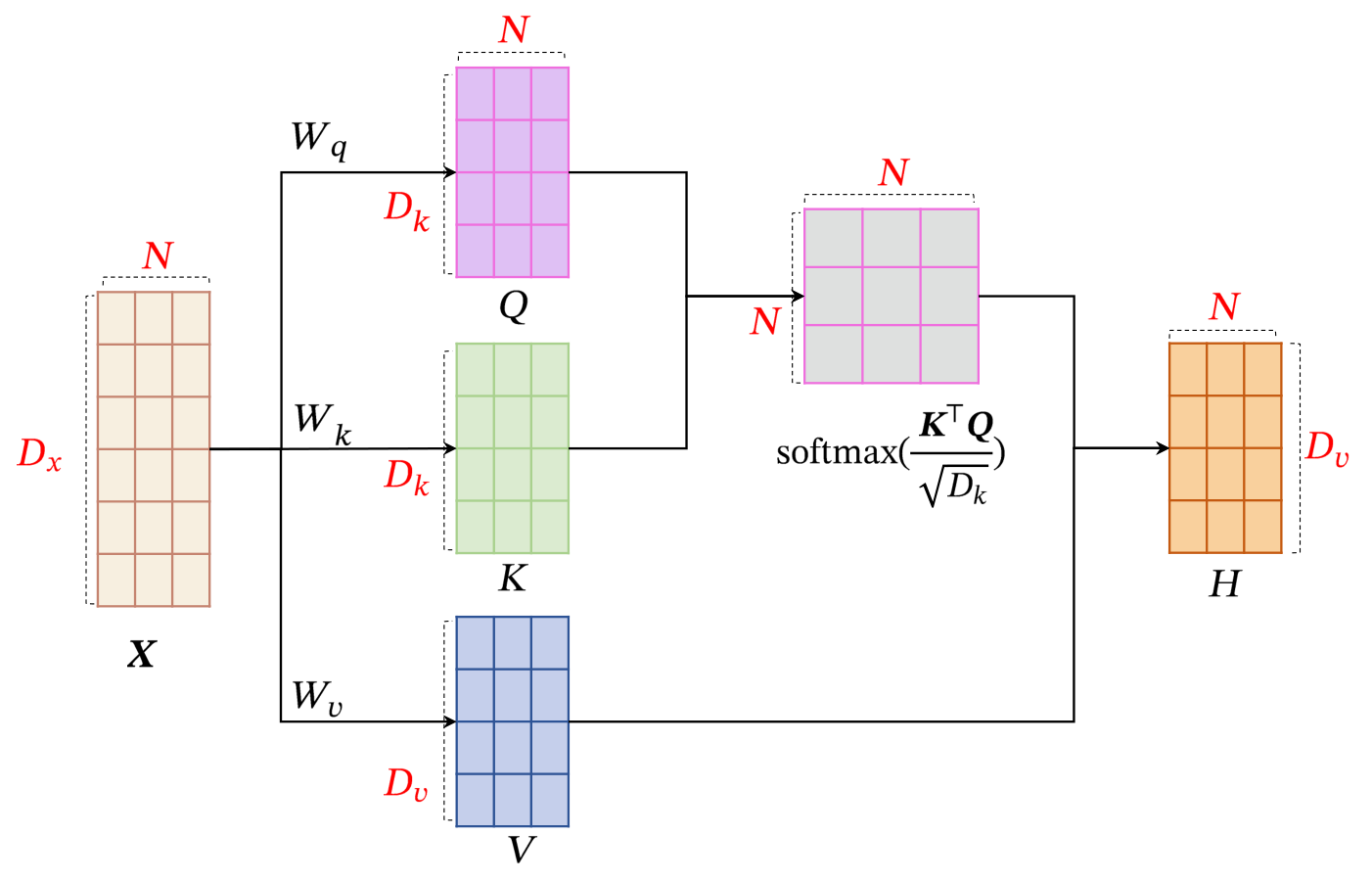
自注意力模型
输入序列为
- 首先生成三个向量序列:
- 计算
: - 如果使用缩放点积来作为注意力打分函数,输出向量序列可以简写为:
你可以尝试用自注意力机制取代 RNN 所做的任何任务。
Transformer Encoder
除了自注意力机制还用到了:
位置编码
Positional Encoding
层归一化
Add & Norm:
- Add — 残差连接
- Norm — 将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛
Transformer-Decoder
Masked 多头注意力机制,在翻译的过程中是顺序翻译的,即翻译完第
复杂度分析
| 模型 | 每层复杂度 | 序列操作数 | 最大路径长度 |
|---|---|---|---|
| CNN | |||
| RNN | |||
| Transformer |
:卷积核大小 :序列长度 :维度