数学基础
线性代数
标量,向量运算 ...
向量
向量范数
满足以下条件的函数
- 非负:
- 正定:
- 齐次:
- 三角不等式:
向量
更一般地:
矩阵
Hadamard 积
点积
矩阵范数
算子(诱导)范数:
设:
则:
算子范数定义:
一般的
常见矩阵范数:
-范数(最大绝对列和):
-范数(谱范数):
等价于
-范数(最大绝对行和):
Frobenius 范数:
微积分
- 次导数:不可求导情况下的导数(左右导数之间的所有值)
| 输出 \ 输入 | 标量 | 向量 | 矩阵 |
|---|---|---|---|
| 标量 | |||
| 向量 | |||
| 矩阵 |
数学优化
(最优化都学过)
概率论
(概率论都学过)
正态分布
信息论
熵(Entropy)
自信息(Self Information)
熵
熵是理论最优平均编码长度,这种编码方式称为熵编码(Entropy Encoding)。
交叉熵(Cross Entropy)
交叉熵是按照概率分布
KL 散度(K-L Divergence)
KL 散度是用概率分布
连续形式:
交叉熵损失
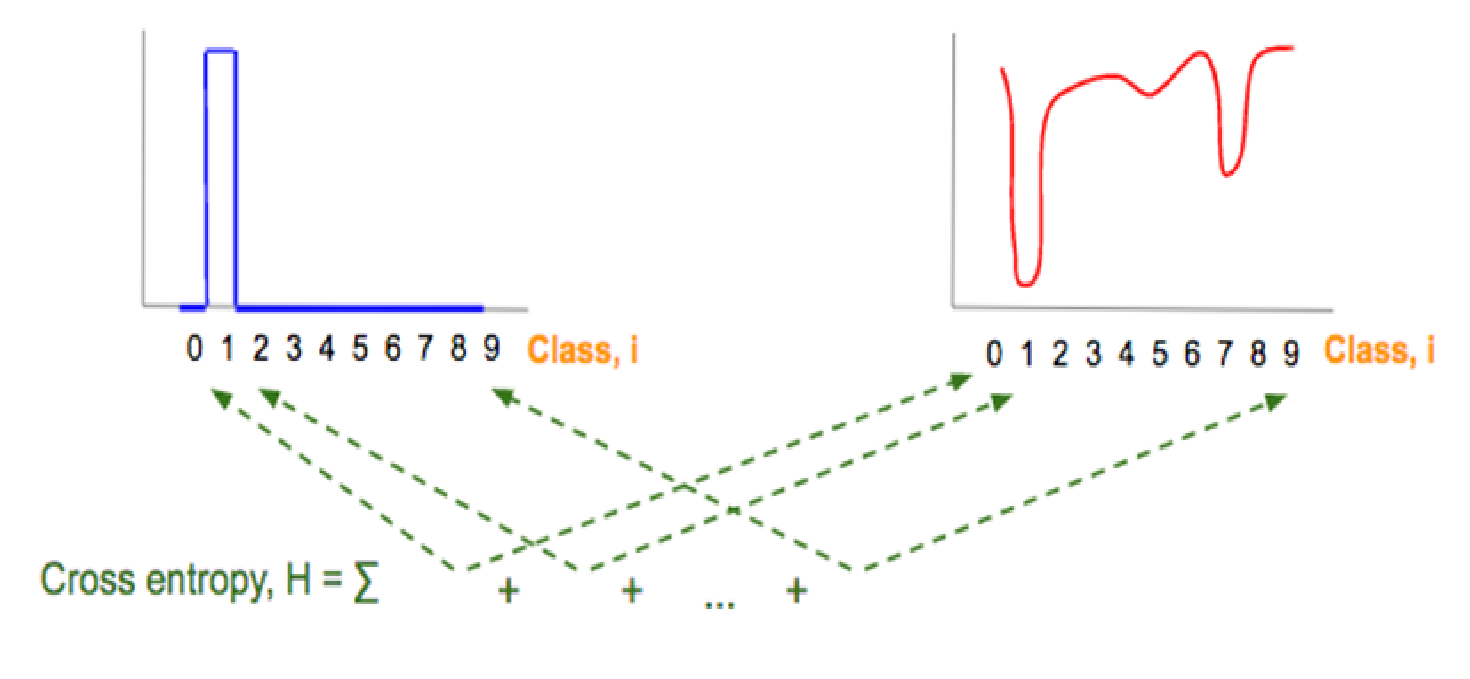
真实概率
负对数似然损失函数
关系(GPT)
text
我们想让预测分布接近真实分布
↓
使用 KL 散度衡量分布差异
↓
去掉与参数无关项
↓
得到交叉熵
↓
one-hot 情况下变成负对数似然 loss。